
Imagine you’re building a magical river that carries information instead of water. This river, called a data pipeline, feeds everything from the recommendations you get online to the scientific discoveries that change the world.
But sometimes, just like a real river, things can go wrong. Maybe the water starts tasting funny, or it gets blocked up completely. This is where you, the data detection, come in!
Also, Gartner’s Data Quality Market Survey showed that the average annual financial cost of poor data is to the tune of $15M. So, data quality problems can disrupt operations, compromise decision-making, and erode customer trust.
This blog is your guide to fixing those glitches and keeping your data river flowing smoothly. We’ll cover how to spot the trouble, grab the right tools, and overcome common issues like dirty water (bad data) and sneaky clogs (transformation errors). So, get ready to roll up your sleeves and become a data pipeline master!
What is data pipeline?
A data pipeline is the digital equivalent of a plumbing system, but instead of water, it transports and processes data. It’s an automated and orchestrated series of steps that take raw data from various sources, transform it into a usable format, and then deliver it to a final destination for analysis or use.
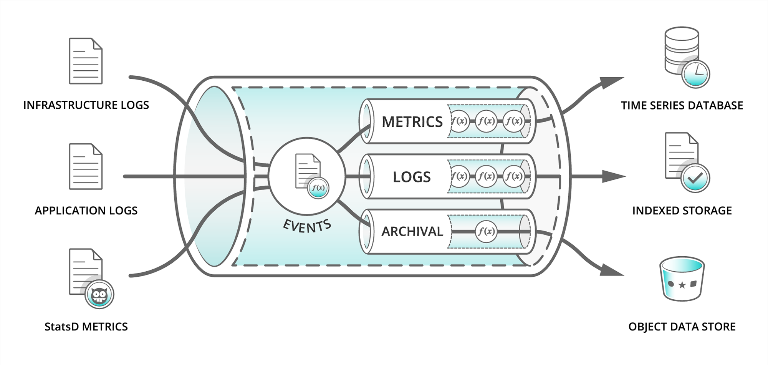
And here are the 7 data quality problems:
- Incomplete data
- Inaccurate data
- Duplicate data
- Inconsistent data
- Outdated data
- Data integrity issues
- Data security and privacy concerns
Before you can fix a problem, you need to know it exists. Identifying data pipeline issues can be like searching for a needle in a haystack. However, by focusing on key signals, you can pinpoint the culprit with laser-like precision:
Data discrepancies: Does the output data differ from expectations? Are there missing values, unexpected formats, or inconsistent records? These discrepancies often point to transformation errors or faulty data sources.
Performance bottlenecks: Is the pipeline sluggish like a hungover sloth? Increased processing time or stalled workflows could indicate inefficient code, resource limitations, or network issues.
Alert fatigue: Data pipelines often raise alarms for potential issues. Are you bombarded with false positives, masking actual problems? Refining your alerting system can separate the wheat from the chaff.
Downstream impact: Are downstream applications reporting corrupted data or experiencing unusual behavior? This could be a symptom of issues further upstream in the pipeline.
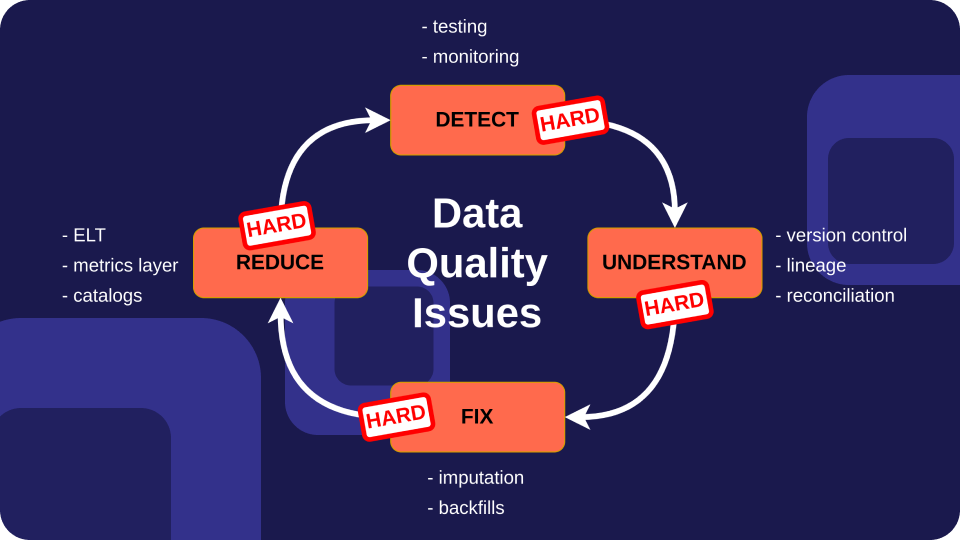
Step 1: The Art of Detection – Identifying the Glitch
Before you can fix a problem, you need to know it exists. Identifying data pipeline issues can be like searching for a needle in a haystack. However, by focusing on key signals, you can pinpoint the culprit with laser-like precision:
Data discrepancies: Does the output data differ from expectations? Are there missing values, unexpected formats, or inconsistent records? These discrepancies often point to transformation errors or faulty data sources.
Performance bottlenecks: Is the pipeline sluggish like a hungover sloth? Increased processing time or stalled workflows could indicate inefficient code, resource limitations, or network issues.
Alert fatigue: Data pipelines often raise alarms for potential issues. Are you bombarded with false positives, masking actual problems? Refining your alerting system can separate the wheat from the chaff.
Downstream impact: Are downstream applications reporting corrupted data or experiencing unusual behavior? This could be a symptom of issues further upstream in the pipeline.
Step 2: Arming Yourself for the Investigation – Essential Tools for Pipeline Forensics
Once you’ve identified the glitch, it’s time to roll up your sleeves and get to work. Here are some essential tools in your data pipeline forensics kit:
Logging and monitoring: Robust logging systems track data flow, highlighting errors and suspicious activity. Tools like Apache Airflow or Luigi provides detailed execution logs and visualizations.
Data profiling and validation: Tools like Great Expectations or Pandas Profiler analyze data quality, identifying discrepancies in schema, format, and statistics.
Testing frameworks: Unit and integration tests ensure individual components and overall pipeline functionality work as expected. Frameworks like Pytest or pytest-airflow can be game-changers.
Debuggers and profilers: When things get really hairy, debuggers like PyCharm or IPython can help step through the code line by line, while profilers pinpoint performance bottlenecks.
Step 3: Taming the Beast – Common Data Pipeline Issues and Fixes
Now, let’s discuss about some common data pipeline issues and how to tackle them:
Data quality issues: Dirty data in, dirty data out. Ensure sources are reliable, validate data formats and values, and implement cleansing routines to scrub away inconsistencies.
Transformation errors: Did those Python loops go rogue? Double-check your transformation logic, test your code thoroughly, and consider unit testing individual components.
Schema mismatch: Does your data speak a different language than your downstream applications? Standardize data formats and schemas across the pipeline, using tools like data contracts or schema.
Resource limitations: Is your pipeline gasping for air? Optimize code for efficiency, scale resources appropriately, and monitor resource utilization to avoid bottlenecks.
Connectivity problems: Are network gremlins causing havoc? Verify that data sources and sinks are accessible, troubleshoot network connectivity, and implement retry logic for transient errors.
Step 4: Embracing the Zen of Data Pipelines – Best Practices for Smooth Sailing
Prevention is always better than cure. Here are some best practices to keep your data pipelines humming like a well-oiled machine:
Modular design: Break down your pipeline into smaller, independent tasks. This makes debugging easier and allows for independent deployment and scaling.
Version control: Track code changes and roll back if needed. Git is your friend!
Documentation: Document your pipeline clearly, including data sources, transformations, and expected outputs. This saves you (and your future self) countless headaches.
Automate testing: Regularly test your pipeline with automated tests to catch regressions and ensure data quality is maintained.
Monitoring and alerting: Continuously monitor your pipeline for performance and potential issues. Set up alerts to catch problems early and avoid downstream impact.
Conclusion,
Remember, debugging data pipelines is an iterative process. Be patient, and methodical, and keep these tips in your arsenal. With the right tools and mindset, you can tame the data monster and ensure your pipelines flow smoothly, fueling your projects with clean, reliable data. Now go forth and conquer!
To read more blogs related to data engineering and data analytics visit Werq Labs.