
Data mining is the use of machine learning and statistical analysis to uncover valuable information and patterns from large data sets.
The adoption of data mining also known as knowledge discovery in databases (KDD) has rapidly evolved over the last decades. As industries continue to evolve, the challenges of scalability and automation are also increasing.
The data mining techniques are used for the 2 main purposes:
- Describe the target data set
- Predict outcomes by machine learning algorithms
The mentioned methods can organize and filter data to avoid major security complications. This can save businesses from fraud and security breaches.
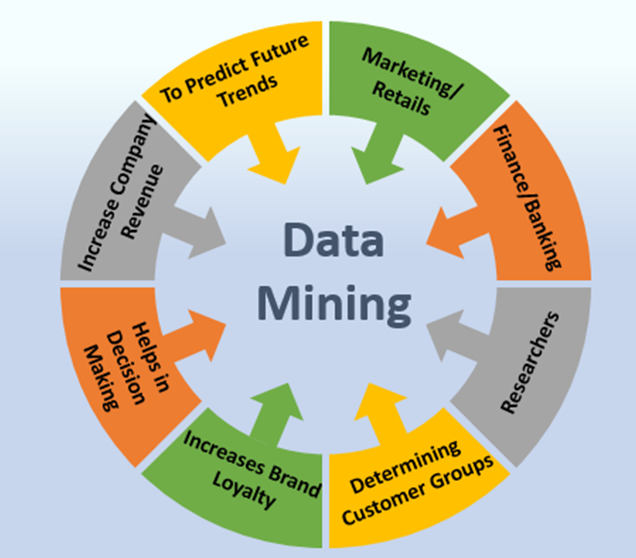
Companies often use data mining software to learn about their customers. It assists them in making marketing strategies, increasing sales, and decreasing costs.
How Data Mining Works
Data mining involves analyzing large data blocks to get meaningful patterns and trends. It is also a market research tool that assists reveal the sentiments or opinions of a given group of people.
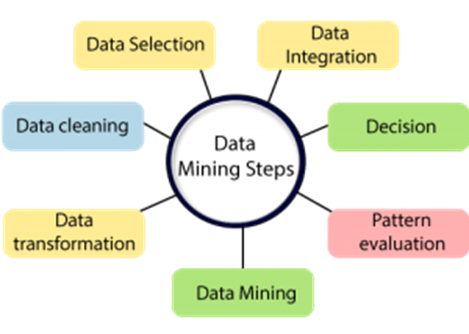
The data mining steps:
Data is collected and loaded into warehouses on-site or through a cloud service.
Business analysts, management teams, and information technology specialists can access the data and decide how to organize it.
Custom application software sorts and arranges data.
The end user provides the data in an easily shareable format, such as a graph or table.
Phases of Data Mining
Data mining, the process of extracting valuable information from large datasets, follows a structured approach. This approach is often represented by a methodology like CRISP-DM (Cross-Industry Standard Process for Data Mining). Here are the key phases involved:
1. Business Understanding
Define Objectives: Clearly articulate the business problem or opportunity you want to address.
Identify Goals: Determine the specific outcomes or insights you seek from the data mining process.
2. Data Understanding
Collect Data: Gather relevant data from various sources.
Explore Data: Analyze the data to identify patterns, inconsistencies, and potential issues.
3. Data Preparation
Clean Data: Address data quality issues like missing values, outliers, and inconsistencies.
Transform Data: Convert data into a suitable format for analysis, such as normalization or feature engineering.
4. Modeling
Select Algorithms: Choose appropriate data mining algorithms based on the problem and data characteristics.
Train Models: Use training data to build predictive or descriptive models.
Tune Parameters: Optimize model performance by adjusting algorithm parameters.
5. Evaluation
Assess Model Performance: Evaluate the accuracy and reliability of the models using appropriate metrics.
Compare Models: Compare different models to identify the best-performing one.
6. Deployment
Integrate Model: Integrate the chosen model into the business environment.
Monitor Performance: Continuously monitor the model’s performance and update it as needed.
Additional Considerations:
Iteration: The data mining process is often iterative, meaning you might need to revisit earlier phases based on findings or challenges.
Ethical Considerations: Ensure data mining practices adhere to ethical guidelines and privacy regulations.
Tools and Techniques: Utilize various tools and techniques, such as statistical methods, machine learning algorithms, and visualization techniques, to extract meaningful insights.
By following these phases and considering the factors mentioned above, you can effectively extract valuable information from your data and make informed decisions.
Common Types of Data Mining
Data mining techniques can be broadly categorized based on their objectives and the types of patterns they seek to discover. Here are some of the most common types:
1. Predictive Data Mining
Classification: Assigns data instances to predefined categories or classes.
Example: Predicting whether a customer will churn or not.
Regression: Predicts numerical values.
Example: Forecasting sales for the next quarter.
Time Series Analysis: Analyzes data collected over time to identify trends, patterns, and anomalies.
Example: Stock price prediction.
2. Descriptive Data Mining
Clustering: Groups data instances based on similarities.
Example: Segmenting customers into different groups based on their purchasing behavior.
Association Rule Mining: Discovers relationships between items in a dataset.
Example: Finding products that are frequently purchased together in a grocery store.
3. Other Techniques
Outlier Detection: Identifies data points that deviate significantly from the norm.
Example: Detecting fraudulent credit card transactions.
Text Mining: Extracts information from unstructured text data.
Example: Sentiment analysis of customer reviews.
Social Network Analysis: Analyzes relationships and interactions within networks.
Example: Identifying influential nodes in a social network.
The choice of data mining technique depends on the specific problem you are trying to solve and the characteristics of your data. By understanding these common types, you can select the most appropriate approach for your data mining tasks.

Best Uses of Data Mining
Data mining, a powerful tool for extracting valuable insights from large datasets, is employed across various industries to drive informed decision-making. Here are some of its most impactful applications:
Business and Marketing
Customer Segmentation: Identifying distinct customer groups based on demographics, behavior, and preferences to tailor marketing campaigns.
Market Basket Analysis: Understanding relationships between products purchased together to optimize product placement and cross-selling strategies.
Customer Churn Prediction: Identifying customers at risk of leaving to implement retention strategies.
Recommendation Systems: Suggesting products or services based on past behavior and preferences.
Healthcare
Disease Diagnosis: Developing predictive models to diagnose diseases early, improving treatment outcomes.
Drug Discovery: Identifying potential drug targets and optimizing drug development processes.
Personalized Medicine: Tailoring treatment plans to individual patients based on their genetic makeup and medical history.
Finance
Fraud Detection: Identifying suspicious transactions and patterns to prevent financial losses.
Risk Assessment: Evaluating creditworthiness and investment risks.
Customer Segmentation: Grouping customers based on financial behavior to offer personalized financial products.
Pattern Recognition: Discovering hidden patterns in scientific data to uncover new insights.
Predictive Modeling: Forecasting future trends and events based on historical data.
Anomaly Detection: Identifying unusual or unexpected events in data.
Other Applications
Social Media Analysis: Understanding public sentiment, trending topics, and social network dynamics.
Image and Video Analysis: Extracting information from visual data, such as object recognition and facial recognition.
Natural Language Processing: Analyzing text data to understand language patterns and sentiment.
In essence, data mining empowers businesses and organizations to make data-driven decisions, improve efficiency, and gain a competitive edge. By uncovering hidden patterns and insights, it enables organizations to optimize operations, enhance customer experiences, and drive innovation.